
The Friday Night Audit That Changed How I Trust My AI Trading System
An emergency-vet waiting room, a Quantreo checklist, and a weekend of system hardening.

Friday night was supposed to be date night. Instead, I was in the emergency vet waiting room auditing a trading system.
By Friday, March 6, 2026, I felt pretty good about FactorForge.
Not done. But real enough to run research, build portfolios, size positions, route orders, and keep enough records to explain what had happened later. Good enough that I’d started to believe the hardest remaining question was probably the model. Good enough to trade my own cash, which was always the point.
That’s enough structure to make a builder feel safe a little too early.
On Friday afternoon, I read Quantreo’s post, The 7 Mistakes I See Every Week (ML), which started me wondering if I’d gotten a little too comfortable.
The piece did what a good article should do. It turned a challenging subject into an accessible checklist.
There wasn’t much to do except wait, worry, and find something concrete to aim that energy at. So I opened the laptop and turned the article into an audit.

Squezel, rendered a little more heroic than she looked that night.
The actual question I asked was:
Hey, given this article, how do we rate? How do we score?
That forced an unflattering question. Does FactorForge just look real, or has it earned that trust?
The useful thing about LLM coding models here wasn’t magic. It was speed. I could turn that question into a real audit in a few minutes instead of promising myself I’d get to it later.
Here’s what I discovered:
my supposed final holdout wasn’t really final
one short-exposure cap was written into the rules but ignored by the live smart-build path
a draft portfolio was too easy to confuse with the live one
stale or fallback broker data could still get treated as good enough for sizing and execution
after the fact, the system still couldn’t tell me how well actuals matched the projections
Four of those failures mapped directly to Quantreo’s checklist.
One of the most important ones didn’t. It was a repo-specific problem where draft state and live state were too easy to blur together.
It was better than I feared but worse than I’d hoped.
Better, because those are the problems of a real system and because the core research logic wasn’t the part that looked broken.
Worse, because there were real problems in the validation ladder and in the logic that allowed strategies to go live.
What the audit actually said
The findings weren’t catastrophic.
They also weren’t clean enough for the amount of trust I had started to give the project.
Three things came out of the audit looking better than I feared.
The line between research and trading is real.
The live system is still recognizably the one I actually tested.
And the portfolio layer already does enough real work that this looks fixable by tightening rules, not by tearing the whole thing down.
The bad news was that several important safeguards were still soft when they should have been firm.
The clearest example was the final release check.
FactorForge had the idea of a final review before a strategy should be trusted with live capital. But in practice, three different ideas had drifted too close together. This looks promising in research isn’t the same as this passed a final independent check, and that isn’t the same as being allowed anywhere near real money.
Those are different claims.
A strategy can be worth keeping, worth studying, even worth moving forward internally, and still not deserve live capital.
The holdout-period issue made that painfully concrete.
A holdout period is just a slice of history you keep untouched until the end. It’s supposed to answer a simple question.
Does this still hold up on data I haven't already let the system impress me with?
The graphic makes it easier to see.
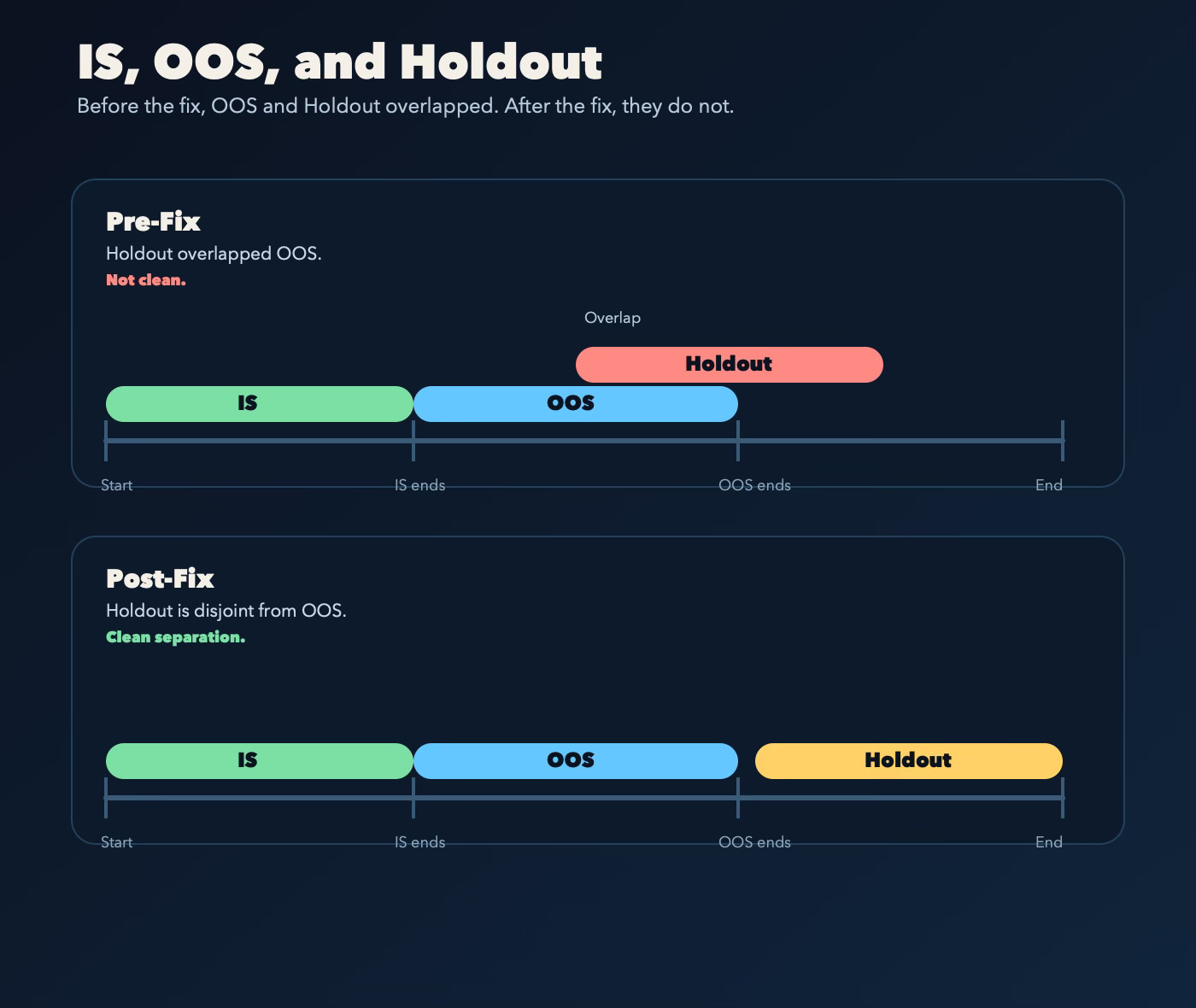
Out-of-sample data, usually shortened to OOS, and holdout data are both “unseen” relative to the training fit, but they’re not the same thing.
OOS is part of the normal research loop. It helps rank, reject, and promote strategies.
Holdout is supposed to stay outside that loop until the very end. That’s what lets it act like a final exam instead of just another checkpoint the system has already been allowed to learn from.
On March 6, the normal research ladder already used out-of-sample data through 2025-12-31, while the supposed final untouched holdout ran from 2024-07-01 through 2025-01-01. So the “final exam” was sitting inside the era I’d already been using to judge strategies, and by then it was more than a year out of date.
That’s not just messy. That’s how a system starts drifting toward overfitting while still telling itself it has one last clean test left.
The same pattern showed up in other places too.
Risk limits existed, but execution didn’t always prove it was trading the final risk-adjusted version.
A draft portfolio could drift too close to what other parts of the system treated as the real one.
Broker data could go stale without the system shutting itself down cleanly.
And one finding wasn’t just conceptual.
The portfolio rules capped total short exposure at 15%, but the default live build could still produce 36% short exposure because it was reading the wrong settings. I care less about the individual bug than about the category.
Configured policy isn’t the same thing as enforced policy.
That became the real theme of the weekend.
What changed for me
Before this audit, I thought the architecture was strong. I thought interpretability was the main weakness. I thought the rest was normal system messiness, and that the next step was adding more models.
After the audit, that felt too forgiving and a little too hopeful.
The better version is harsher. The architecture is strong enough for the weak points to have shifted. The main risks are now trust-boundary failures between layers, not bad models. And I’ve still got more infrastructure to harden before I expand exploration.
Dog is fine now, by the way.
How Quantreo’s Checklist Scored Against FactorForge
The audit produced 10 concrete findings. Some mapped directly to Quantreo’s seven mistakes. One of the most important ones didn’t. It was a repo-specific issue around draft state versus live state.
For this post, I collapsed the 10 findings into five categories that I think are more reusable for anyone building a research or trading stack.

The five categories that mattered most
1. The final holdout wasn’t actually final
This was the biggest one.
FactorForge already had the idea of a final release check, but the boundary wasn’t clean. The normal research test window and the supposed final holdout were overlapping, the final review window was stale, and the live system didn’t require a real approval record.
The dates tell the story.
The normal research test window ran through 2025-12-31. The supposed super-holdout was 2024-07-01 to 2025-01-01. By Friday, March 6, 2026, that meant the “final untouched test” was both overlapping and stale.
Once that happens, the last clean test stops being a last clean test. It starts becoming part of the broader selection process, which is exactly how you inch toward overfitting while still talking like you’re being careful.
That also meant the system was borrowing confidence from a gate that wasn’t actually binding.
The fix was to separate three states that had drifted too close together. Passing research means a strategy is worth keeping. Final approval means it passed a true last review on untouched data. Permission to trade means the system is allowed to use that exact approved version.
That’s still one of the most important distinctions in the whole stack.
2. A draft portfolio was too easy to confuse with the real one
This was the repo-specific problem that kept showing up underneath everything else.
One file had quietly become too many things at once. It was the latest draft, the thing preview screens looked at, the thing monitoring compared against, and something dangerously close to the live baseline.
In practical terms, that meant a new rebalance draft could replace what the UI and monitoring surfaces appeared to treat as the current portfolio before any execution happened.
That’s fine in a toy system. It’s not fine once the system is making real decisions around it.
The rule I wanted after the audit was simple.
Building a draft must not change what the system treats as live.
That sounds obvious. It gets less obvious once one mutable file starts acting like draft, preview, baseline, and truth at the same time.
The implication is simple. If the system can’t answer “what book am I actually comparing the broker against right now?” then monitoring, previews, and execution can all sound more trustworthy than they are.
The work here was less about fancy logic and more about honesty. A draft should be a draft. A live portfolio should be the live portfolio. The system shouldn’t blur the two.
3. One risk cap was real on paper and broken in the live build
This was the cleanest live-path bug in the audit.
The configured total short cap was 15%.
The default live smart-build path could still produce 36%.
The rule itself wasn’t missing. The operator-side rebalance flow respected it. The live smart-build path was reading the wrong settings.
The lesson was simple.
If a control matters, the live path has to prove it used that control.
4. Stale broker data was too close to tradeable truth
This boring category can invalidate all the glamorous ones.
FactorForge had ways to keep operating when broker data was stale, partial, or clearly unreliable. That isn’t automatically bad. It can be useful for diagnostics and previews.
What’s bad is letting that lower-quality picture quietly inherit the same authority as data you’re willing to trade on.
For example, if fresh brokerage prices for positions are missing, a system might fall back to cached account state or approximate values based on average cost. That can be good enough to keep a dashboard alive. It isn’t good enough to size or execute live trades.
That’s also the kind of mistake LLM coding tools love to introduce. They add a fallback so the code “keeps working,” but unless you’re careful, the fallback can cross the line from diagnostics into execution. I’ve seen that pattern often enough now that I treat it as something to audit for directly.
Some of what I found here was exactly that pattern. The behavior was acceptable for diagnostics, but not okay if it didn’t clearly tell the human that the system had dropped to a lower-quality version of reality.
That pushed the implementation toward freshness checks, clearer rules for different trading situations, and hard rejection of unreliable position data before live execution.
Again, not glamorous. Still essential.
5. I had records, but not yet a clean explanation loop
This remains the most important unfinished category.
FactorForge already had a lot of record-keeping. It knew which strategies fed into each position, kept lot-level records and ledger records, and had ways to reconcile those records back to the broker.
But that isn’t yet the same thing as being able to answer, cleanly and repeatedly, what the system expected a strategy or group of strategies to do, what actually happened live, where the gap came from, and what decision should change as a result.
One important record-keeping defect did get fixed. The default live build was dropping some of the “where did this position come from?” context, and that’s now preserved.
That helps. What it still doesn’t give me is the full loop I actually want.
live result -> explanation -> changed research behavior
That’s the part that still needs real work.
What changed in the system
The point of an audit isn’t to produce a better diary.
The point is to turn vague discomfort into system changes.
1. I separated research success from live approval
This was the biggest shift.
I turned the final review gate into something load-bearing. That meant cleaner testing windows, frozen review cohorts, an actual approval process, and live eligibility tied to a specific approved strategy version.
passed the research tests no longer gets to pretend it means deserves live capital.
2. I cleaned up what counts as draft versus live state
Drafts, execution records, and the active portfolio now live in different places. Rebuilding a portfolio no longer silently rewrites the thing monitoring appears to compare against.
That sounds procedural. It changes what the system is allowed to treat as real.
That same stretch also fixed the short-cap bug and preserved one important piece of “where did this position come from?” context that the live build had been dropping.
3. I made the live path less willing to improvise
The live path now has to prove it is trading the risk-adjusted portfolio, using fresh account and position data, and operating on well-formed files. Bad broker data is much less likely to sneak through as “good enough.”
That was the point. The live system should be less willing to improvise.
What still isn’t good enough
I don’t want to overstate where the project landed after one weekend.
The front end of the process is in much better shape. The remaining work is different now. It’s less about “should this thing be allowed into live trading at all?” and more about “once it’s live, can I measure it honestly enough to learn from it?”
Three gaps still stand out.
1. Expectation versus reality
I want FactorForge to keep cleaner records of what each strategy or group of strategies was expected to do, what actually happened, and where the gap came from.
That’s partly a reporting problem.
It’s mostly a trust problem.
2. Governance
The system still needs explicit downgrade and freeze logic.
Right now I can describe the spirit of those decisions. I can’t yet point to a mature, data-backed layer that says this group of strategies is no longer earning capital, this strategy needs another round of testing, or this mismatch is large enough to freeze deployment.
That’s still too much operator judgment and not enough system behavior.
3. Learning from live results
This one’s the hardest, and maybe the most important.
The system is much better now at deciding what is allowed into live trading.
It still isn’t strong enough at turning live behavior back into changed research, changed capital allocation, or changed rules for what gets moved forward.
That’s the part FactorForge still doesn’t do cleanly. Validating entry turned out to be easier than learning from live outcomes.
The checklist I’d use on any system now
Here’s the reusable part I wanted.
If you want the compact version first, here it is.

If I were auditing another AI investing system tomorrow, I’d start here.
1. What exactly earns the right to touch real money?
If the answer is some fuzzy version of “it passed research,” the system isn’t done.
Passing research, final approval, and permission to trade should be different states with different records and different failure modes.
2. Is the draft portfolio separate from the real one?
A new build should create a draft, not quietly mutate the thing the rest of the system treats as live.
If preview, monitoring, and execution all orbit the same mutable file, trust is already too loose.
3. Are risk controls available, or are they required?
A risk limit shown in the UI isn’t the same thing as a rule the system refuses to break.
Configured limits don’t count unless the live system is forced to honor them.
4. What quality of truth is allowed to size or trade?
Old, partial, damaged, or estimated data may be useful for diagnostics.
It shouldn’t quietly inherit the same authority as data you’re willing to trade on.
5. Can the system explain outcomes in the same language it uses to allocate capital?
If capital is allocated by strategy, group of strategies, exposure, and overall portfolio setup, the explanation of results needs to come back in those same units.
Otherwise the operator ends up with stories instead of feedback.
6. What explicitly reduces trust?
Every real system needs a crisp answer to what freezes capital, what forces another round of testing, what downgrades a group of strategies, and what counts as a tolerable miss versus an unacceptable one.
If those rules only appear after the pain arrives, they aren’t rules yet.
The lesson
The flattering question for an AI investing stack is How smart is the model?
The useful question is What exactly has to be true before this system deserves more trust?
Once the machinery starts looking real, the easiest way to fool yourself is usually not one bad model. It’s one weak handoff inside a pretty convincing system.